이번엔 딥러닝 심화에 걸맞게 YOLO와 VGG를 실습했습니다.

VGG와 YOLO는 모두 컴퓨터 비전에서 객체 인식을 위한 딥러닝 모델이지만, 그 구조와 사용 목적이 다릅니다.
VGG (Visual Geometry Group)
- 구조: VGG는 깊은 합성곱 신경망(CNN)으로, 주로 이미지 분류에 사용됩니다. VGG16과 VGG19는 각각 16층과 19층의 깊이를 가지고 있습니다.
- 특징: 단순하고 규칙적인 구조로, 3x3 합성곱 필터와 2x2 최대 풀링 레이어를 반복적으로 사용합니다.
- 장점: 이미지 분류에서 높은 정확도를 자랑하며, 다양한 이미지 데이터셋에서 좋은 성능을 보입니다.
- 단점: 계산 비용이 높고, 실시간 처리에는 적합하지 않습니다.
YOLO (You Only Look Once)
- 구조: YOLO는 객체 검출을 위한 one-stage detector로, 이미지 전체를 한 번에 처리하여 객체의 위치와 종류를 예측합니다.
- 특징: 이미지 전체를 그리드로 나누고, 각 그리드 셀에서 객체의 존재 여부와 바운딩 박스를 예측합니다.
- 장점: 실시간 객체 검출이 가능하며, 속도가 매우 빠릅니다.
- 단점: 작은 객체나 복잡한 배경에서는 성능이 떨어질 수 있습니다.
왜 나눌까?
- 사용 목적: VGG는 주로 이미지 분류에 사용되며, YOLO는 실시간 객체 검출에 사용됩니다.
- 특장점: VGG는 높은 정확도를, YOLO는 빠른 속도를 제공합니다.
- 응용 분야: VGG는 이미지 분류, YOLO는 자율 주행, 보안 감시 등 실시간 응용에 적합합니다
이 두 모델은 각각의 특성과 장점을 살려 다양한 비전 솔루션에 활용됩니다. 어떤 용도로 사용하시려는지에 따라 적합한 모델을 선택하는 것이 중요합니다.
1: YOLOv7 살펴보기 2: YOLOv8 기반으로 이미지, 동영상, 실시간 웹캠 물체 분석 인식

특장점이 다달라서 기술마다 사용되는 게 다릅니다!

<<요양로봇>>
1. 이미지 분류 - 입모양 분류
class: 개폐상태 (on/off, size)
이미지 셋
입을 닫은상태, 중간 상태, 열은 상태를
클래스로 만들고 폴더 정리하고
촬영.
사람 몇명으로 데이터 만들지
내일까지 yolo 이미지 셋
계속 업데이트하면서 학습시키는 게 중요함.
식판 - 숟가락 YOLO
object detecting
대상은 가만히 있는다.

라고 수업시간 중간에 프로젝트 회의 ㅎㅎ
로봇 팔을 파이썬으로 미리 제어해두기

모든 서보 각도값을 출력합니다:[28.47, 44.64, 73.47, 10.19, 1.75, -2.02]
입의 사이즈
뭔가
환자 입의 좌표가 필요한데
엔드이펙터 설정을 해야 합니다.
카메라 띄우니까 친구 자는 거 떴네요.

https://github.com/HumanSignal/labelImg/releases
Releases · HumanSignal/labelImg
LabelImg is now part of the Label Studio community. The popular image annotation tool created by Tzutalin is no longer actively being developed, but you can check out Label Studio, the open source ...
github.com
이거 다운로드하여서 사용하는 것.

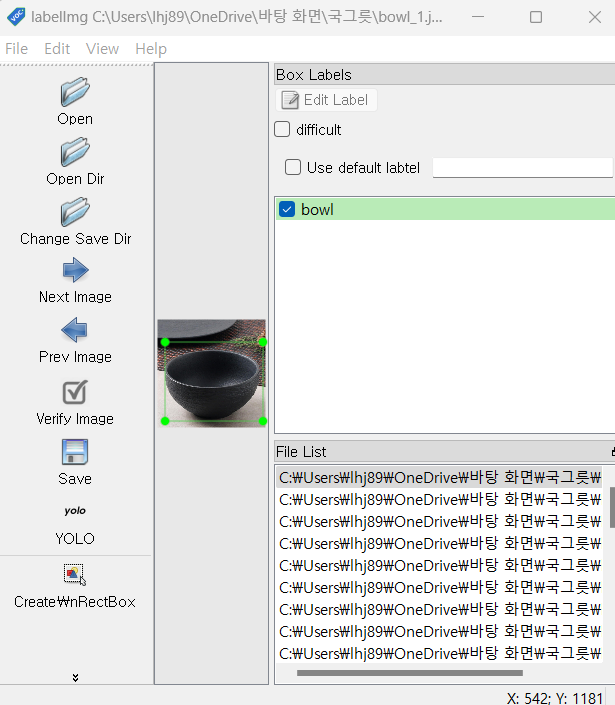
w키 누르고 사이즈 맞추고 pascal을 yolo로 바꾸고 save 눌러주면 txt파일로 바뀝니다,
그걸 다 지정해 주
그리고 2개 분류할 거면

요래 2개 나눠서 저장해줘야 함.

근데 에러뜸
왜지?? 왜지???

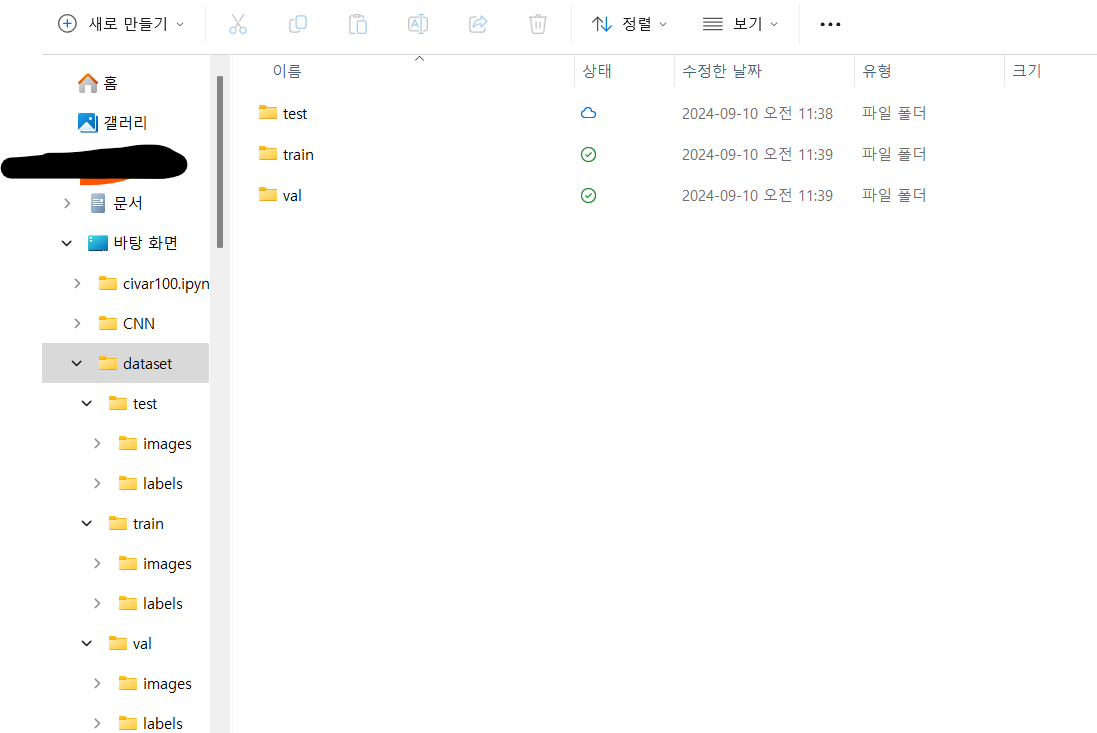
images와 labels로 나누어서 따로 다 넣어둬야 합니다.

이런 식으로...
그리고 라벨도 다 바꿔야 해요...
1개밖에 테스트 안 할 거라...



오오 돌아간다 드디어

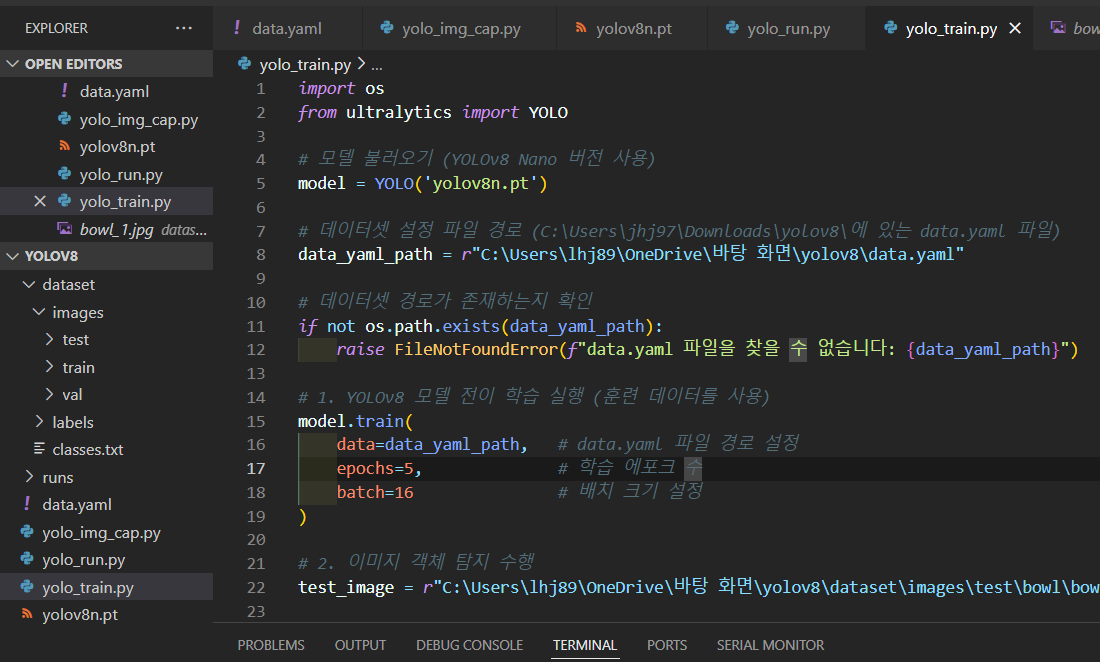
그 dataset.yaml에 기본경로 path설정 코드를 추가했습니다.


밖으로 빼기
run 돌리면 해결

폴더 올립니다!!
를 하려니까 업로드가 안돼서
직접 생성하시면 되는데
폴더 관리 잘해주시고
train이후에
best.py 찾아서 경로 꼭 옮겨 주세요..!!
data.yaml
path: C:\Users\lhj89\OneDrive\바탕 화면\yolov8\dataset # 데이터셋의 기본 경로
train: images/train # 훈련 데이터 경로
val: images/val # 검증 데이터 경로
test: images/test # 테스트 데이터 경로 (필요시)
nc: 1 # 클래스 수 (예: 국그릇)
names: ['bowl'] # 클래스 이름
img_cap.py
import cv2
import os
# import time
def capture_image():
image_count = 0
cap = cv2.VideoCapture(0)
save_directory = "img_capture"
os.makedirs(save_directory, exist_ok=True)
while True:
ret, frame = cap.read()
cv2.imshow("Webcam", frame)
key = cv2.waitKey(1)
if key == ord("c"):
file_name = f"{save_directory}/img_{image_count}.jpg"
cv2.imwrite(file_name, frame)
print(f"Image saved. name:{file_name}")
image_count += 1
elif key == ord("q"):
break
cap.release()
cv2.destroyAllWindows()
capture_image()
train.py
import os
from ultralytics import YOLO
# 모델 불러오기 (YOLOv8 Nano 버전 사용)
model = YOLO('yolov8n.pt')
# 데이터셋 설정 파일 경로 (C:\Users\jhj97\Downloads\yolov8\에 있는 data.yaml 파일)
data_yaml_path = r"C:\\Users\\lhj89\\OneDrive\\바탕 화면\\yolov8\\data.yaml"
# 데이터셋 경로가 존재하는지 확인
if not os.path.exists(data_yaml_path):
raise FileNotFoundError(f"data.yaml 파일을 찾을 수 없습니다: {data_yaml_path}")
# 1. YOLOv8 모델 전이 학습 실행 (훈련 데이터를 사용)
model.train(
data=data_yaml_path, # data.yaml 파일 경로 설정
epochs=5, # 학습 에포크 수
batch=16 # 배치 크기 설정
)
# 2. 이미지 객체 탐지 수행
#test_image = r"C:\\Users\\lhj89\\OneDrive\\바탕 화면\\yolov8\\dataset\\images\\test\\bowl_1.jpg"
# 파일 경로 확인
if not os.path.exists(test_image):
raise FileNotFoundError(f"테스트 이미지 파일을 찾을 수 없습니다: {test_image}")
# 이미지에 대한 예측 수행
results = model(test_image)
# 3. 결과 시각화 및 저장 (리스트 내 개별 결과에 대해 처리)
for result in results:
result.show() # 탐지 결과 시각화
result.save("best.pt") # 결과를 저장할 디렉토리run.py
import cv2
from ultralytics import YOLO
# 훈련된 YOLOv8 모델 로드
model = YOLO('best.pt')
# 웹캠 열기
cap = cv2.VideoCapture(0)
# 클래스 이름과 색상 매핑
class_colors = {
'class1': (0, 255, 0), # 초록색
'class2': (0, 0, 255), # 빨간색
'class3': (0, 255, 255) # 노란색
}
# 모델의 클래스 이름 가져오기
class_names = model.names
while True:
ret, img = cap.read()
if not ret:
print("Failed to capture image")
break
# 웹캠 이미지 크기
h, w = img.shape[:2]
# 모델 입력 크기로 이미지 크기 조정
img_resized = cv2.resize(img, (640, 640))
# 모델을 사용하여 이미지에서 객체 감지
results = model(img_resized)
# 감지된 객체들 처리
for result in results:
boxes = result.boxes
if boxes is None:
continue
for box in boxes:
cls_id = int(box.cls[0])
confidence = box.conf[0]
xyxy = box.xyxy[0].cpu().numpy()
# 클래스 이름과 색상
class_name = class_names[cls_id]
color = class_colors.get(class_name, (255, 255, 255))
# 바운딩 박스 좌표를 원본 이미지 크기로 변환
x1, y1, x2, y2 = [int(coord) for coord in xyxy]
# 원본 이미지와 모델 입력 이미지의 크기 비율 계산
x1 = int(x1 * w / 640)
y1 = int(y1 * h / 640)
x2 = int(x2 * w / 640)
y2 = int(y2 * h / 640)
# 바운딩 박스 그리기
cv2.rectangle(img, (x1, y1), (x2, y2), color, 2)
cv2.putText(img, f'{class_name} {confidence:.2f}', (x1, y1 - 10),
cv2.FONT_HERSHEY_SIMPLEX, 0.5, color, 2)
# 결과를 웹캠 비디오 피드에 표시
cv2.imshow('Webcam', img)
# 'q' 키를 눌러 종료
if cv2.waitKey(1) == ord('q'):
break
# 웹캠과 모든 OpenCV 윈도우 해제
cap.release()
cv2.destroyAllWindows()

수정 더 넣어야 함...


첨언:
아 여러분 사진을 한 번에 찍고 두 개로 나누면 분류가 잘 안 되니까
두 개로 나누어서 하는 게 좋습니다!
그럼 고생하십시오!